
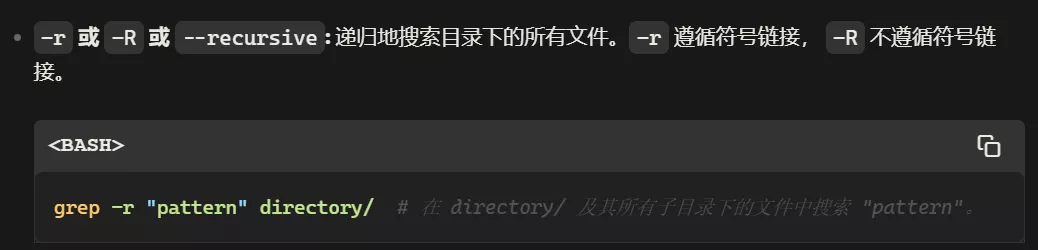
grep命令
grep -i “word” filepath -->忽略大小写匹配
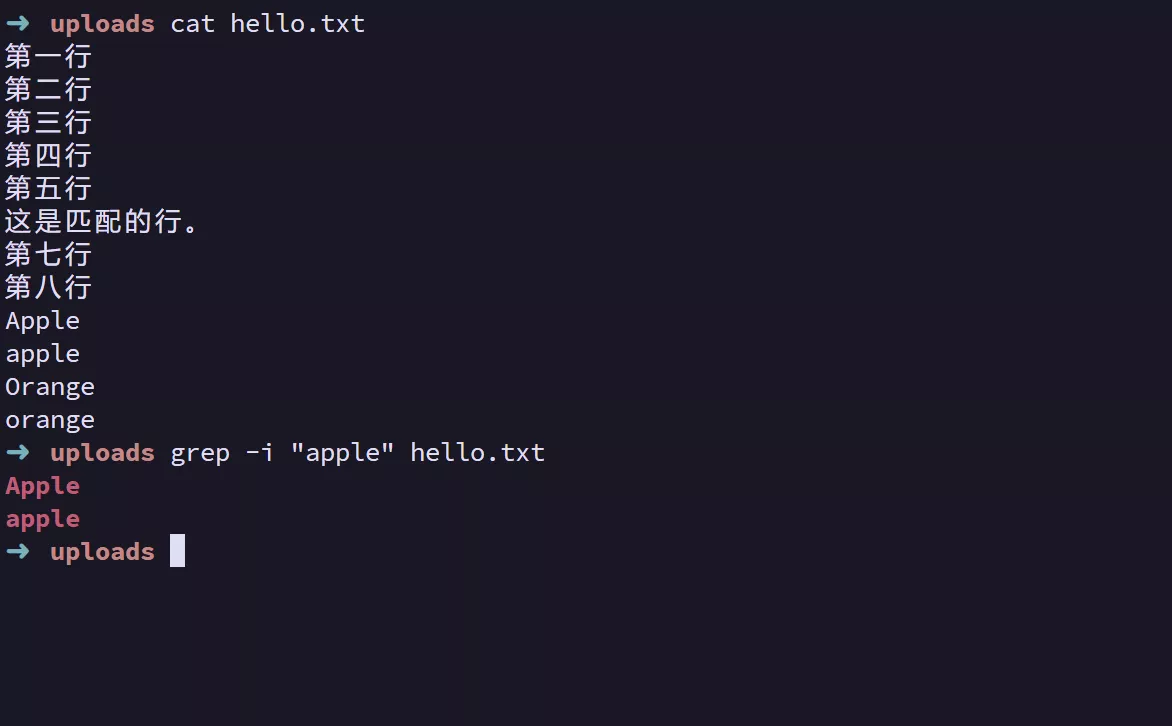
grep -v “word” filepath --> 反向匹配
# 显示所有不包含 “error” 的行。
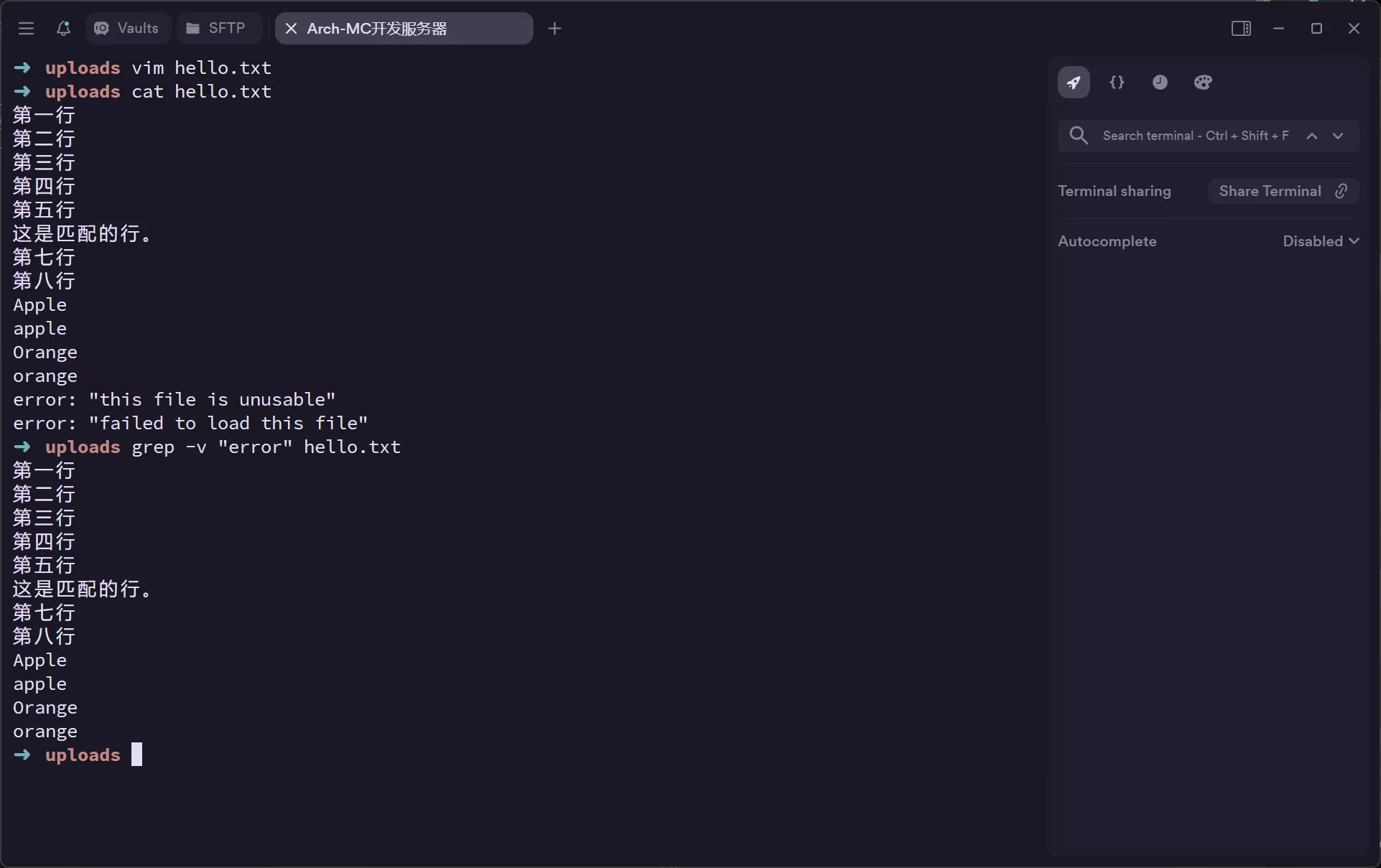
grep -w “word” filepath --> 匹配完整单词
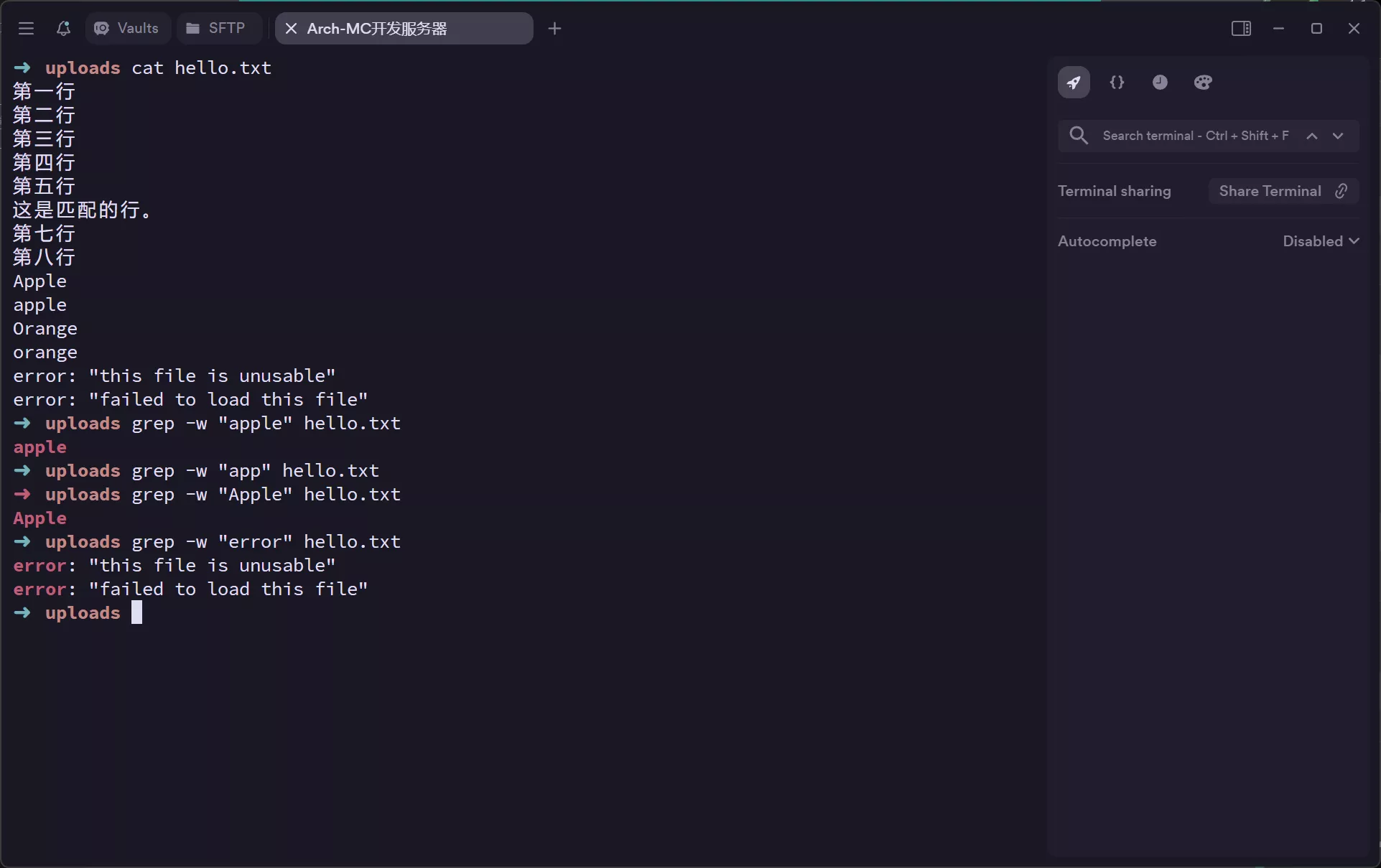
grep -c “pattern” filepath # 输出匹配 “pattern” 的行数

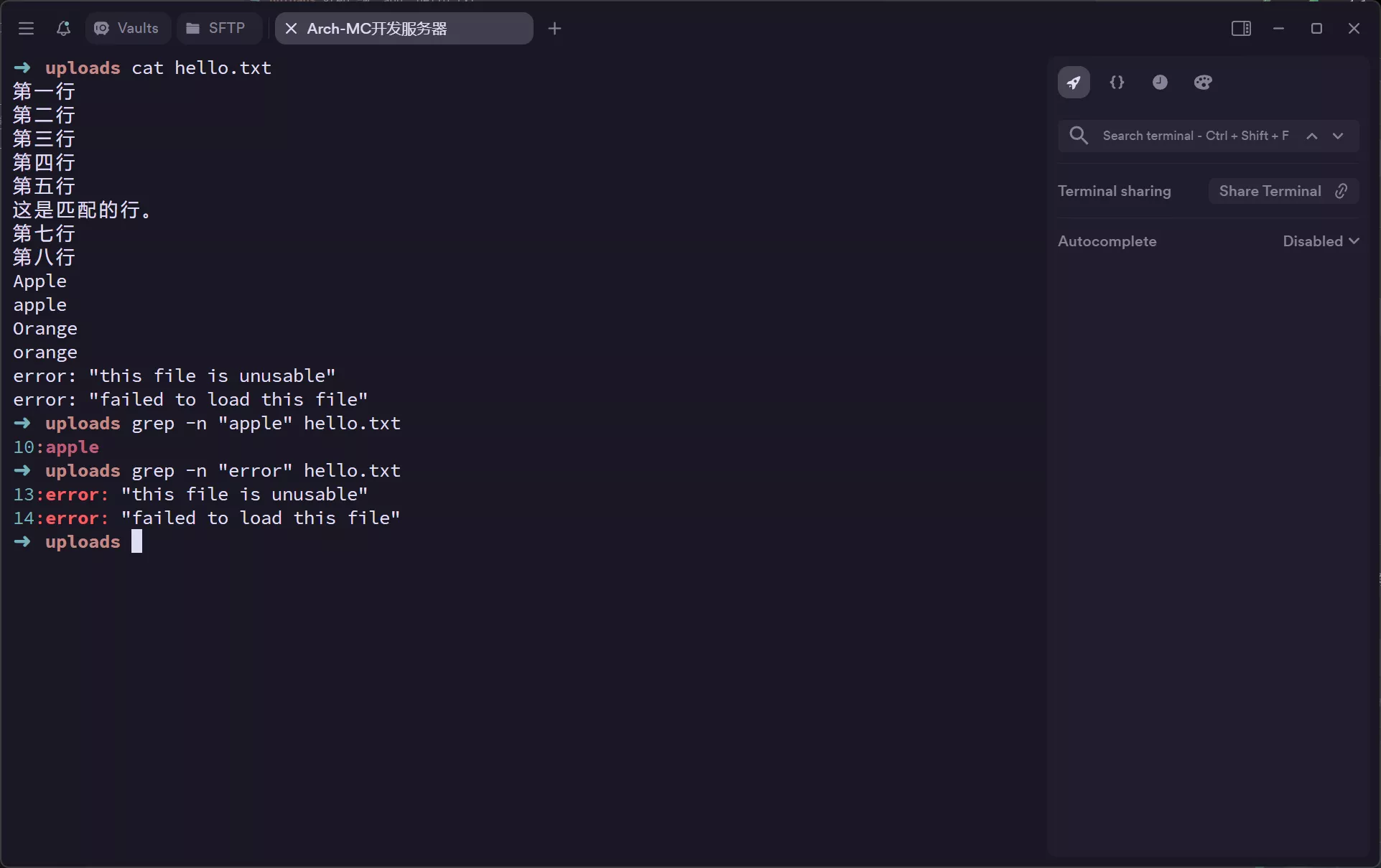
grep -n “pattern” filepath 显示匹配行及其行号。
grep -r “pattern” directory/ 递归搜索目录下所有文件
grep -l “pattern” *.txt 只显示包含匹配内容的文件名,不显示具体的行

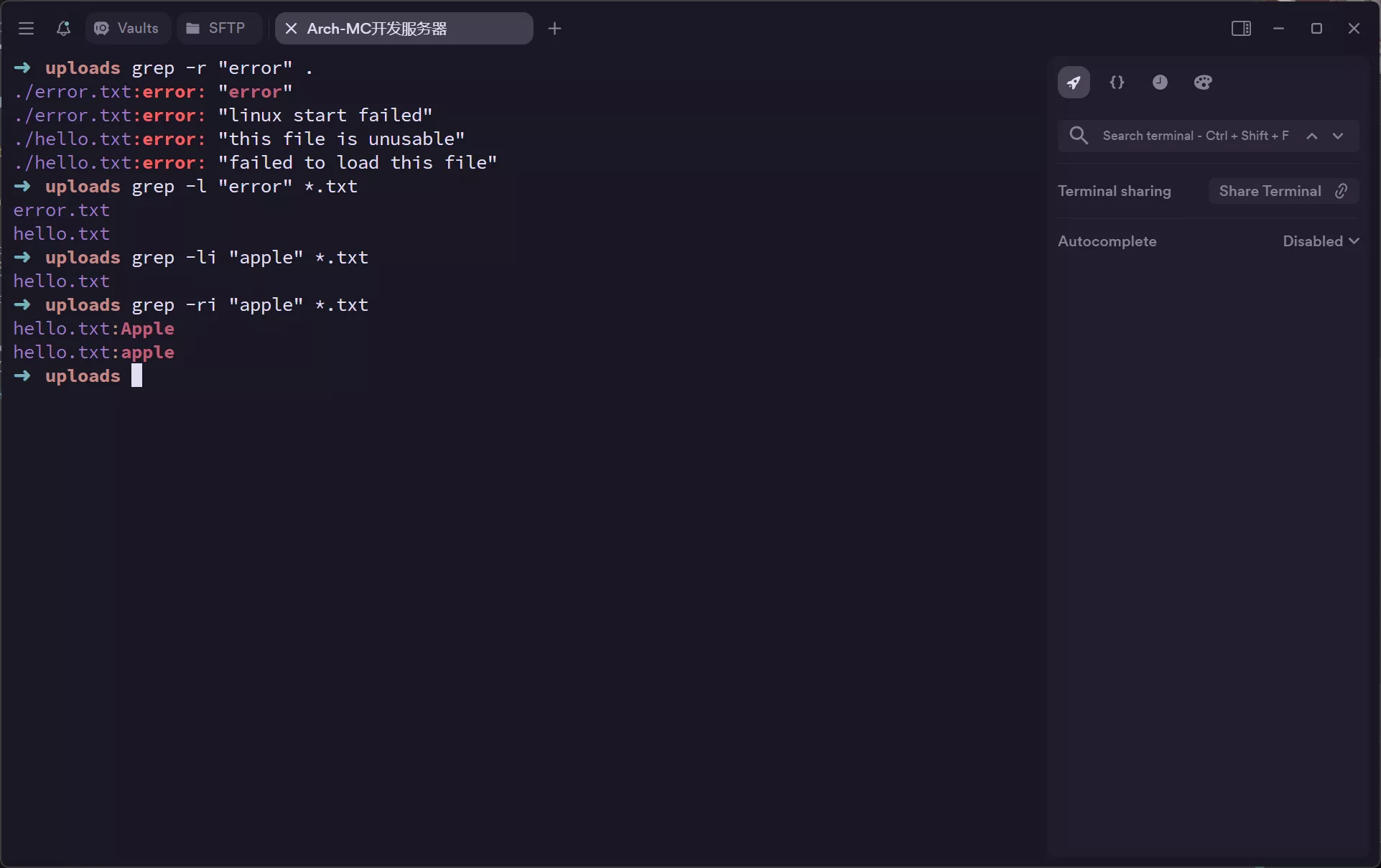
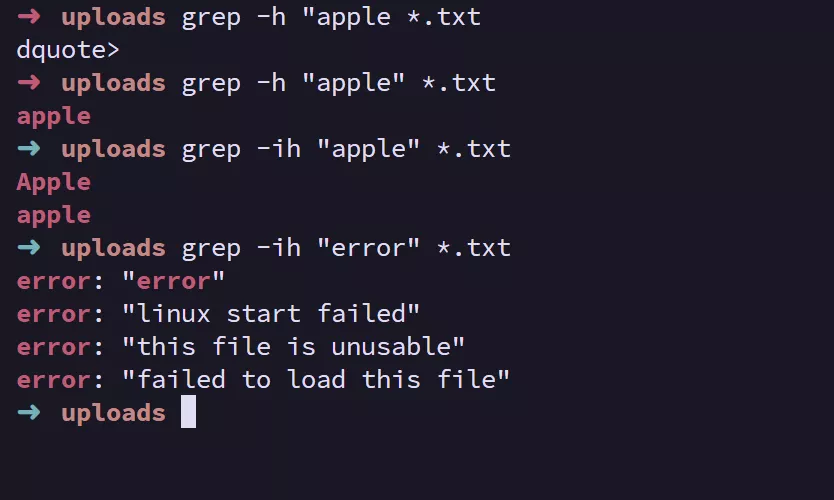
grep -h “pattern” filepath 在多文件搜索的时候不显示文件名

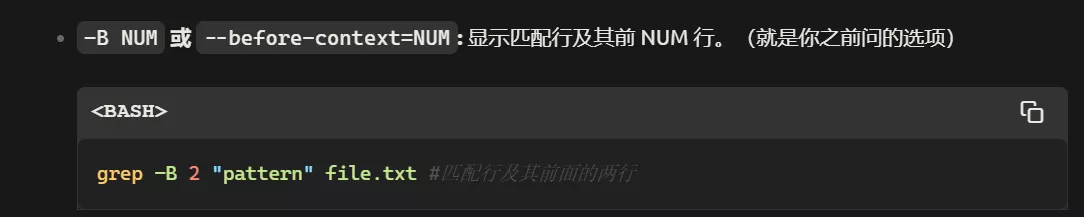
grep -B Number “pattern” filepath 显示匹配行及其前 NUM 行。(就是你之前问的选项)
-B NUM 或 --before-context=NUM: 显示匹配行及其前 NUM 行。(就是你之前问的选项)
grep -C Number "pattern " filepath 显示匹配行及其前后 NUM 行。
好的,下面更全面地介绍一下 grep 命令的用法:
基本语法:
grep [选项] 模式 [文件...]
grep: 命令本身。[选项]: 可选的参数,用来控制grep的行为。模式: 你要搜索的字符串或正则表达式。[文件...]: 要搜索的文件名。如果没有指定文件名,grep会从标准输入读取数据。
常用选项:
-
-i或--ignore-case: 忽略大小写进行匹配。grep -i "hello" myfile.txt # 匹配 "hello"、"Hello"、"HELLO" 等。 -
-v或--invert-match: 反向匹配,只显示不包含模式的行。grep -v "error" logfile.txt # 显示所有不包含 "error" 的行。 -
-w或--word-regexp: 仅匹配整个单词。grep -w "word" myfile.txt # 只匹配单独的 "word",不匹配 "sword" 或 "wordy"。 -
-c或--count: 只显示匹配的行数,不显示具体的行。grep -c "pattern" myfile.txt # 输出匹配 "pattern" 的行数 -
-n或--line-number: 显示匹配行及其行号。grep -n "pattern" myfile.txt #输出匹配行的内容及其行号 -
-r或-R或--recursive: 递归地搜索目录下的所有文件。-r遵循符号链接,-R不遵循符号链接。grep -r "pattern" directory/ # 在 directory/ 及其所有子目录下的文件中搜索 "pattern"。 -
-l或--files-with-matches: 只显示包含匹配内容的文件名,不显示具体的行。grep -l "pattern" *.txt # 显示当前目录下所有包含 "pattern" 的 txt 文件名。 -
-h或--no-filename: 在多文件搜索时,不显示文件名。grep -h "pattern" file1.txt file2.txt -
-E或--extended-regexp: 使用扩展正则表达式。 这意味着你可以使用更复杂的模式匹配规则,例如+,?,|,()等。grep -E "pattern1|pattern2" file.txt #匹配包含 "pattern1" 或 "pattern2" 的行。 -
-F或--fixed-strings: 将模式视为固定字符串,而不是正则表达式。 这可以提高搜索速度,尤其是在模式包含正则表达式特殊字符时。grep -F ".*" file.txt # 将 ".*" 视为普通字符串,而不是正则表达式的通配符。 -
-o或--only-matching: 只显示匹配的部分,而不是整行。grep -o "[0-9]\+" file.txt # 只显示文件中的数字序列。 -
-A NUM或--after-context=NUM: 显示匹配行及其后 NUM 行。grep -A 2 "pattern" file.txt #匹配行及随后的两行 -
-B NUM或--before-context=NUM: 显示匹配行及其前 NUM 行。(就是你之前问的选项)grep -B 2 "pattern" file.txt #匹配行及其前面的两行 -
-C NUM或--context=NUM: 显示匹配行及其前后 NUM 行。grep -C 2 "pattern" file.txt #匹配行及其前后的两行
示例:
-
在文件中搜索字符串:
grep "example" myfile.txt # 在 myfile.txt 中搜索包含 "example" 的行。 -
从标准输入搜索:
cat myfile.txt | grep "example" # 将 myfile.txt 的内容通过管道传递给 grep 进行搜索。 -
使用正则表达式:
grep "^[A-Z].*\.txt$" # 搜索以大写字母开头,以 ".txt" 结尾的行。 -
组合使用选项:
grep -in "error" logfile.txt # 忽略大小写,显示包含 "error" 的行及其行号。
正则表达式基础 (grep -E):
使用 -E 选项时,可以使用更复杂的正则表达式。 一些常用的正则表达式元字符包括:
.(点号): 匹配任意单个字符。*(星号): 匹配前一个字符零次或多次。+(加号): 匹配前一个字符一次或多次。?(问号): 匹配前一个字符零次或一次。|(竖线): 逻辑 “或”,匹配多个模式中的任何一个。()(括号): 用于分组,并可以用来捕获匹配的文本供后续引用。[](方括号): 匹配方括号中的任意一个字符。 例如,[abc]匹配a,b或c。^(脱字符): 匹配行的开头。$(美元符): 匹配行的结尾。
使用总结:
grep 是一个非常强大的文本搜索工具,熟练掌握它的各种选项和正则表达式可以大大提高你在 Linux 命令行下的工作效率。记住,可以通过 man grep 命令查看 grep 的完整文档,了解所有可用的选项和更高级的用法。